Free LLM Router: Live Routing for OpenRouter's Free Models
Original: https://www.jacobchak.com/blog/free-llm-router
Published: Feb 17, 2026
Read Time: 5 min
Free LLM Router: https://freellmrouter.com
GitHub: https://github.com/kaihochak/free-llm-router
TL;DR
- What it is: An API that returns a live, customizable list of currently-available free models on OpenRouter.
- Why: Free models are volatile (rate limits, random errors, disappearing endpoints).
- Who it's for: <em style="color: #b45309;">MVPs, demos, and proofs of concept. For production, use paid models for more stable performance.</em>
The Problem
I used OpenRouter's rotating set of free-tier models (see OpenRouter Pricing) to prototype AI features at near-zero cost. This worked well for prototypes, but free models can be rate-limited, error out, or disappear - so demos break unless you constantly update a fallback list.
- Rate limiting - You hit the free tier limit and your app stops working mid-demo.
- Random errors - 4xx/5xx/timeouts.
- Models disappearing - A model you used last week is gone today.
- Stale fallback lists - You hardcode a list of backup models, but within a week half of them are unavailable or rate-limited.
To avoid this, I built Free LLM Router, a simple API that returns a live, customizable list of available free models on OpenRouter.
What Free LLM Router Does
OpenRouter also recognizes the problem of free model instability and has released a Free Models Router. If this works for you, great! But if you want more control on the specific set of models you get, or want to filter by specific capabilities, or want a more reliable ranking system based on community feedback, Free LLM Router is for you.
Quick comparison:
- OpenRouter Free Models Router: convenient default.
- Free LLM Router: filters, exclusions, community reliability ranking, and optional self-hosting.
1. A live-updated list for fallback rotation
Continuously tracks which free models on OpenRouter are actually available right now, so your app can rotate through them.
Without Free LLM Router:
// Before: you have to maintain this list in code
const models = [
'google/gemini-2.0-flash-exp:free',
'google/gemma-3-27b-it:free',
'mistralai/mistral-small-3.1-24b-instruct:free',
'qwen/qwen3-coder:free',
'nvidia/nemotron-3-nano-30b-a3b:free',
'mistralai/devstral-2512:free',
'moonshotai/kimi-k2:free',
'google/gemma-3-12b-it:free',
];
for (const id of models) {
const result = await tryModel(id);
if (result) return result;
}
Even with this, you might still hit errors in production:
[Error] Rate limited upstream
type: AI_APICallError
url: https://openrouter.ai/api/v1/chat/completions
statusCode: 429
message: Provider returned error
details: mistralai/mistral-small-3.1-24b-instruct:free is temporarily rate-limited upstream
[Error] No endpoint available
type: AI_APICallError
url: https://openrouter.ai/api/v1/chat/completions
statusCode: 404
message: No endpoints found for google/gemini-2.0-flash-exp:free
With Free LLM Router, all you need is one API call:
import { getModelIds } from './free-llm-router';
// After: models come from one API call
const { ids: models } = await getModelIds();
for (const id of models) {
const result = await tryModel(id);
if (result) return result;
}
2. Customizable to your needs (via Web UI)
Filter by use case (reasoning, vision, long context, code), model health status, or exclude specific models you don't want.
Configure your preferences through a web interface instead of changing code every time a model goes down.
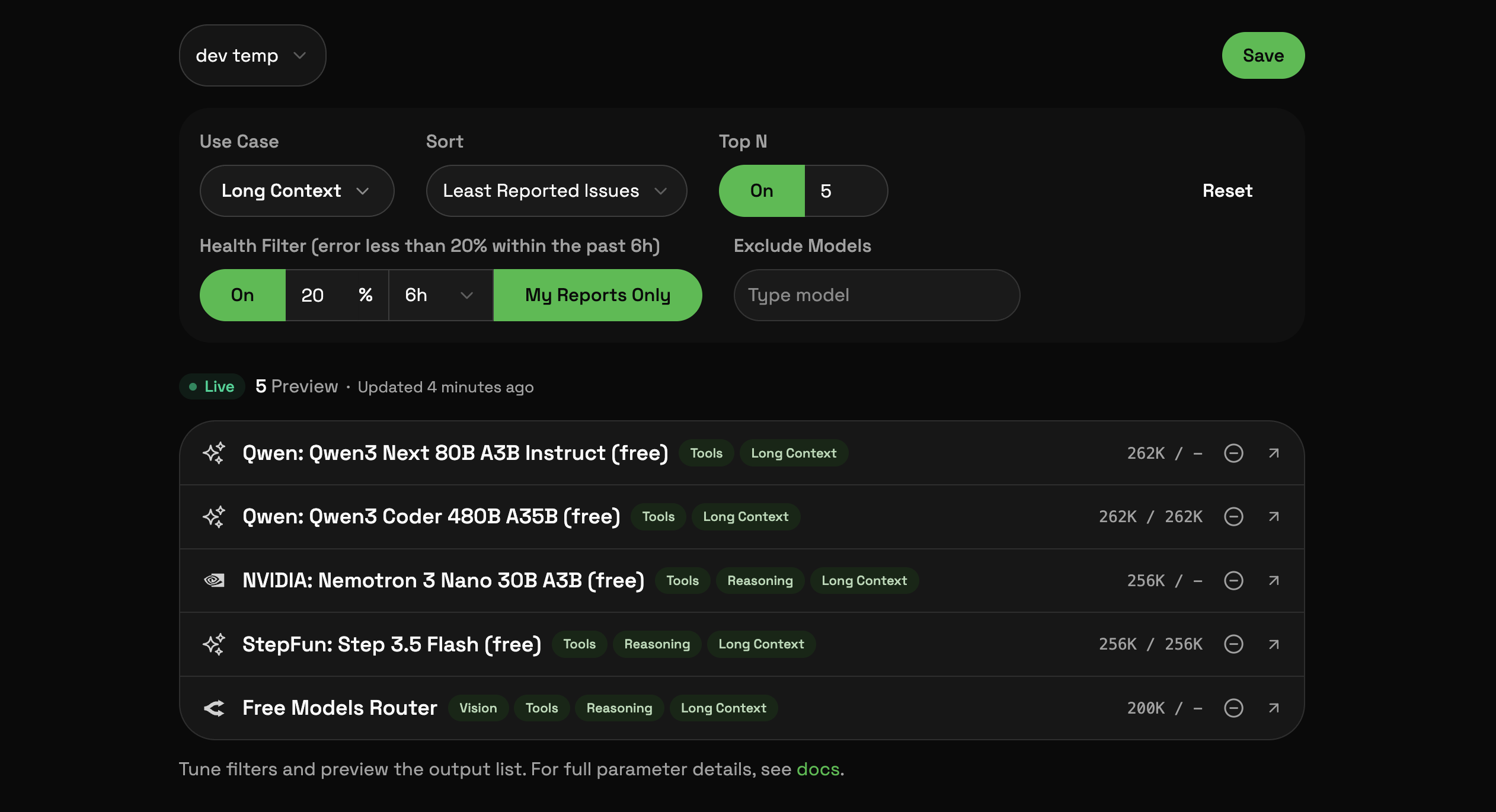
3. Community-driven reliability ranking + model exclusions
You send success/failure feedback after each model call, and flaky models get ranked lower over time.
Blacklist specific models so they never show up in your results, no matter how "available" they are.
4. Completely open source and free
Open source, with a hosted option if you just want to use it (and self-hosting if you want full control).
How to Use It
The basic flow in your app looks like this:
import { getModelIds, reportSuccess, reportIssue, issueFromStatus } from './free-llm-router';
try {
// getModelIds() with no params applies your saved configured params automatically
const { ids: freeModels, requestId } = await getModelIds()
for (const id of freeModels) {
try {
const res = await client.chat.completions.create({ model: id, messages });
// submit success feedback
reportSuccess(id, requestId);
return res;
} catch (e) {
const status = e.status || e.response?.status;
// submit issue feedback
reportIssue(id, issueFromStatus(status), requestId, e.message);
}
}
} catch {
// E.g. return await client.chat.completions.create({ model: 'anthropic/claude-3.5-sonnet', messages });
}
throw new Error('All models failed');
For full setup instructions and API reference, check out the documentation.
How It Works Under the Hood
The system is straightforward:
- Model discovery - Periodically (on a short schedule) checks OpenRouter's model list for free-tier models and updates the internal registry.
- Health tracking - Monitors model availability and response quality through a feedback loop. When users report errors or poor responses, the model's reliability score drops.
- Ranked responses - When you request models, they're sorted by a composite score that factors in reliability, capability match, and recent performance.
- Smart filtering - You can filter by capabilities (reasoning, vision, long context, code, etc.), so you get models that actually suit your use case rather than a generic list.
Privacy: Feedback only includes model id + success/failure + optional status/error string. It does not include prompts or user content.
The feedback mechanism is what makes this different from just scraping OpenRouter's model list yourself. Over time, the rankings get better as more people use it and flaky models get pushed down.
Limitations
- Availability isn't quality - A model being up doesn't mean it's good for your use case.
- Free models change - Behavior, speed, and availability can shift without notice.
- Retries/timeouts still matter - A router helps, but you still want per-request timeouts and backoff.
- Production stability - For production workloads, pick paid models for more predictable performance.
Why I Built This
It was purely for myself initially. I used it for several projects and demos, and it saved me a ton of time and headaches. I realized it could be useful for other developers facing the same issues with free LLM models, so I cleaned it up and released it as an open source project.
Support My Work
If you find Free LLM Router useful or want to support more open-source projects like this, consider sponsoring me:
<iframe src="https://github.com/sponsors/kaihochak/card" title="Sponsor kaihochak" height="120" width="600" style="border: 0; max-width: 100%;"></iframe>